기계가 인간처럼 스스로 학습하여 새로운 상황에 대한 답을 낼 수 있도록 훈련시키는 것이다. 앞의 문장에서도 알 수 있듯이, 현재 광범위한 사업 분야에 적용, 응용되고 있는 인공지능의 핵심 개념이자 기술 중 하나다. 흔히 딥러닝(Deep Learning)이라고 하는 심층신경망 학습은 이 머신러닝의 하위 분류이다. 인공지능-머신러닝-딥러닝의 관계는 인공지능에 대해 배우는 교육과정에서 가장 먼저 배우게 된다. 간단히 그림으로 나타내면 아래와 같다.
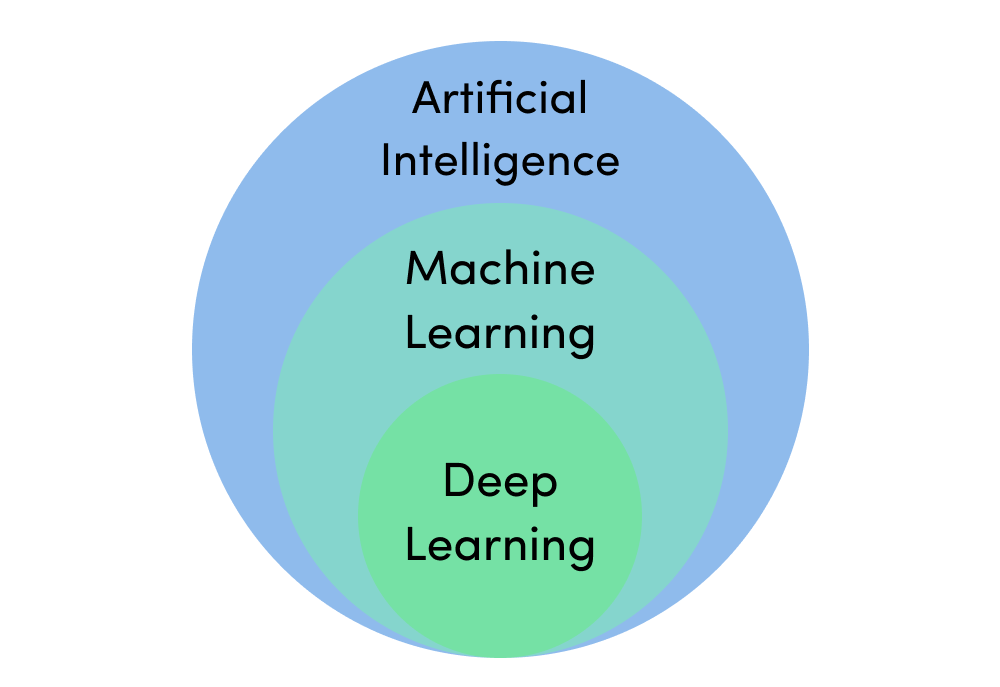
머신 러닝은 다시 크게 세 가지 분류로 나뉘게 되는데, 지도학습, 비지도학습, 강화학습이다. 이 중 초보자가 중점적으로 배우게 되는 것은 지도학습과 비지도학습이다. 이 두 학습의 간단한 차이를 나타낸 그림을 한 번 보자.
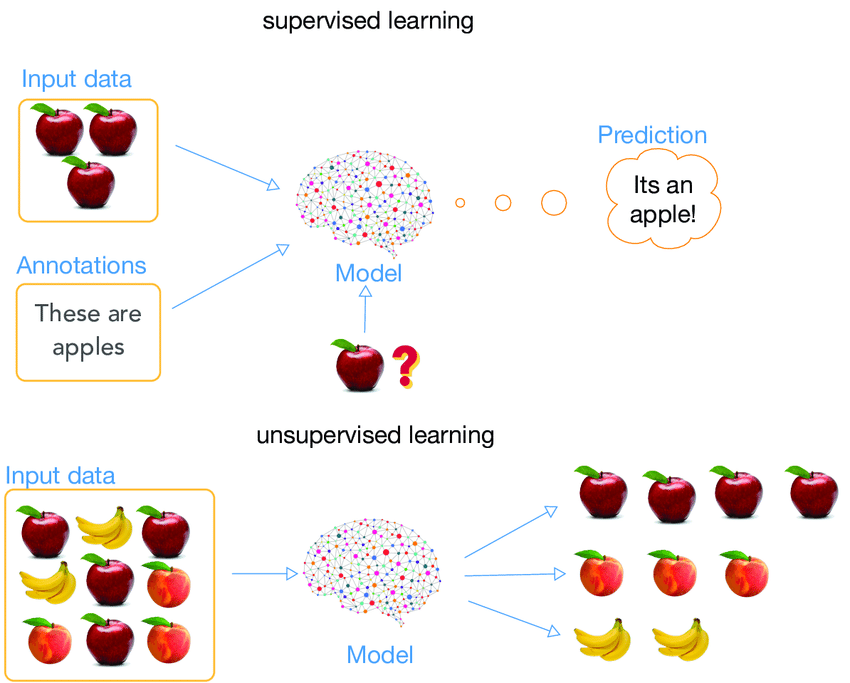
- 지도학습(Supervised Learning)
- 문제-정답으로 구성된 데이터 세트로 컴퓨터(기계)를 훈련시켜 새로운 문제를 잘 풀 수 있도록 한다. 쉽게 수능 시험을 위해 전년도 모의고사나 각종 문제집에 수록된 실전 모의고사 문제를 수없이 푸는 수험생들을 떠올리면 된다. 이렇게 반복해서 많은 문제들(학습 데이터)을 풀며 수험생들은 출제 문제의 유형과 최적의 풀이과정을 습득하며(훈련), 이 과정에서 학습이 잘 될 경우 수능(새로운 문제)에 응시할 때 보다 많은 정답을 맞힐 확률이 올라간다.
- 반드시 정답이 존재해야 한다는 특징이 있다. 정답이 없거나 정답을 정의하기 힘든 문제는 지도학습으로 해결하기 힘들다.
- 분류(Classification)와 회귀(Regression)으로 나뉜다. 수학 문제로 비유하면 분류는 오지선다형, 회귀는 직접 답을 계산해 적어야 하는 주관식 문제로 생각할 수 있다.
- 비지도학습(Unsupervised Learning)
- 지도학습과 달리 정답이 없는 데이터 세트로 모델을 훈련시킨다. 컴퓨터는 각 데이터 간의 특성을 파악하여 여러 개의 그룹으로 분류한다. 마구 뒤섞인 문서파일을 여러 폴더에 깔끔히 분류하는 것을 생각해보자. 물론 이 분류 기준은 여러 가지가 될 수 있다. 작성자명일 수도, 작성된 연월일수도, 소속된 프로젝트일 수도 있다. 중요한 것은 지도학습과 달리 정답이 존재하지 않는다는 것이다.
- 클러스터링(Clustering)이 여기에 속한다.
- 강화학습(Reinforcement learning)
- 보상과 벌칙을 통해 컴퓨터가 더 많은 보상을 받는 방향으로 학습할 수 있도록 한다. 기준이 기준인만큼 보상과 벌칙이 명확히 정의될 수 있어야 한다.
- 게임 분야에서 많이 사용된다.
'What is □?' 카테고리의 다른 글
| 24_파라미터(Parameter, 매개변수)란 무엇인가? (0) | 2021.07.05 |
|---|---|
| 23_레거시 시스템(Legacy system)이란 무엇인가? (0) | 2021.06.28 |
| 21_파티셔닝(Partitioning), 파티션(Partition)이란 무엇인가? (0) | 2021.06.14 |
| 20_샤딩(Sharding)이란 무엇인가? (0) | 2021.06.10 |
| 19_리프트 앤 시프트(Lift and shift, 전면 전환)이란 무엇인가? (0) | 2021.06.05 |


